Amazon MemoryDB for Redis: A Marriage of Speed and Durability
Forget trade-offs, Imagine a “database” that delivers in-memory speed with the 11 9’s durability. It was a joy to read the paper “Amazon MemoryDB: A Fast and Durable Memory-First Cloud Database”. This paper triggered me to share what I admire about its innovative approach. It fundamentally challenges the notion that speed and durability are opposing forces in database design.
MemoryDB breaks the mold by decoupling the storage engine (Redis) from the durability layer (transaction log). Technically, the concept of separating storage and durability isn’t entirely new. Most systems do partial de-coupling (shipping transaction logs off boxes). However, complete decoupling, focus on in-memory performance, and the level of consistency it offers makes it unique.
Redis does not offer a replication solution that can tolerate the loss of nodes without data loss, or can offer scalable strongly-consistent read
Paper highlights that while Redis boasts impressive microsecond latencies and the ability to perform complex operations, it falls short when it comes to offering a replication solution that can tolerate data loss without sacrificing availability. Specifically, while Redis offers options for point-in-time snapshots and append-only files (AOF) for persistence, these methods can introduce trade-offs between data durability and performance. For instance, AOF with synchronous fsync calls for every update can significantly impact performance but ensures data durability in case of a failure.
… this does not prevent other clients accessing the same shard to observe unacknowledged updates as WAIT does not synchronize replication globally on a shard
For strong consistency, Redis offers WAIT command, while useful for enforcing synchronous replication on specific clients, but only blocks specific clients, ensuring updates they issue are acknowledged before continuing but does not synchronize replication across the entire shard.
The paper emphasizes the core innovation:
This separation allows the storage engine (Redis) to scale and optimize for in-memory performance, while the transaction log service can be independently scaled and optimized for durability.
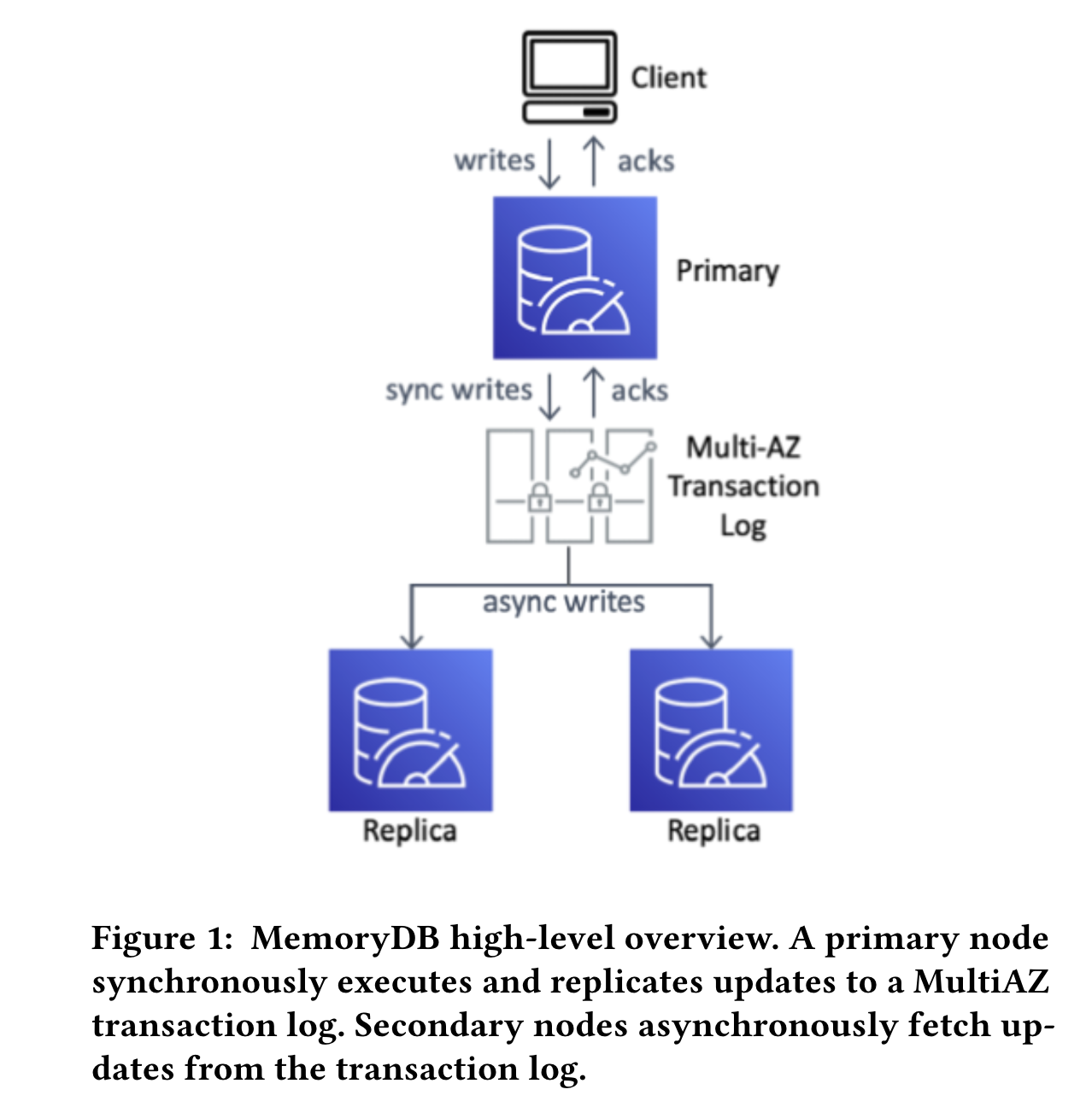
This decoupling ensures that writes aren’t held hostage by durability concerns, allowing both speed and data protection to flourish. Unlike traditional Redis, which prioritizes speed by acknowledging writes before replication occurs, MemoryDB prioritizes data integrity. MemoryDB first replicates the write operation to the transaction log and only acknowledges the write to the client after successful replication to the configurable number of replicas. This synchronous replication ensures that even in the event of a primary node failure, the data remains safe and recoverable. In addition, Reads on the primary node are guaranteed to be consistent with the latest committed writes. By fundamentally rethinking the relationship between in-memory performance and data durability.
Behind the scenes, MemoryDB is also playing a smart game with snapshots. Snapshots are like frozen moments in time of your database, crucial for recovering data in case of major mishaps. The paper explains the dilemma
Depending on the data size and write throughput, the time to create a complete snapshot can range from tens of minutes to hours…
Frequent snapshots minimize the data you might lose in a failure, but they eat up storage and can even make your database sluggish while they’re created.
The paper acknowledges that Redis’ traditional snapshotting method, BGSave, can significantly impact performance. BGSave, short for “Background Save,” is the traditional method used by Redis to create snapshots. While it serves the purpose of capturing a point-in-time copy of your data for recovery, it comes at a performance cost. It mentions that
BGSave forks the Redis process to create a child process to perform snapshots
When a BGSave is initiated, Redis creates a fork of the main process. This essentially creates a duplicate of the entire Redis instance, which consumes a significant amount of system resources. During the forking process, both the original and the child process (created for the snapshot) are actively working on the same dataset. This duplication of effort can lead to requests take longer to process as the system juggles managing the live data and creating the snapshot (latency) and the overall number of operations Redis can handle per second (throughput) dips as resources are diverted to the snapshotting process.

This performance trade-off inherent in Redis highlights a key area where MemoryDB breaks new ground. Unlike Redis, MemoryDB isolates snapshots on a separate cluster. As the paper states,
MemoryDB uses a separate cluster with multiple replicas to store snapshot data…

This eliminates the resource competition, minimizing the impact of backups on your applications. Customers don’t need to worry about reserving resources or scheduling snapshots around peak hours. MemoryDB manages it all with only minimal, temporary spikes in latency, ensuring a seamless user experience. Customers get the peace of mind that comes with reliable backups, without sacrificing the speed and availability that are non-negotiable for mission-critical applications.
Overall, MemoryDB isn’t just offering an incremental upgrade. It’s a paradigm shift.


Comments
Post a Comment