Amazon MemoryDB for Redis: A Marriage of Speed and Durability
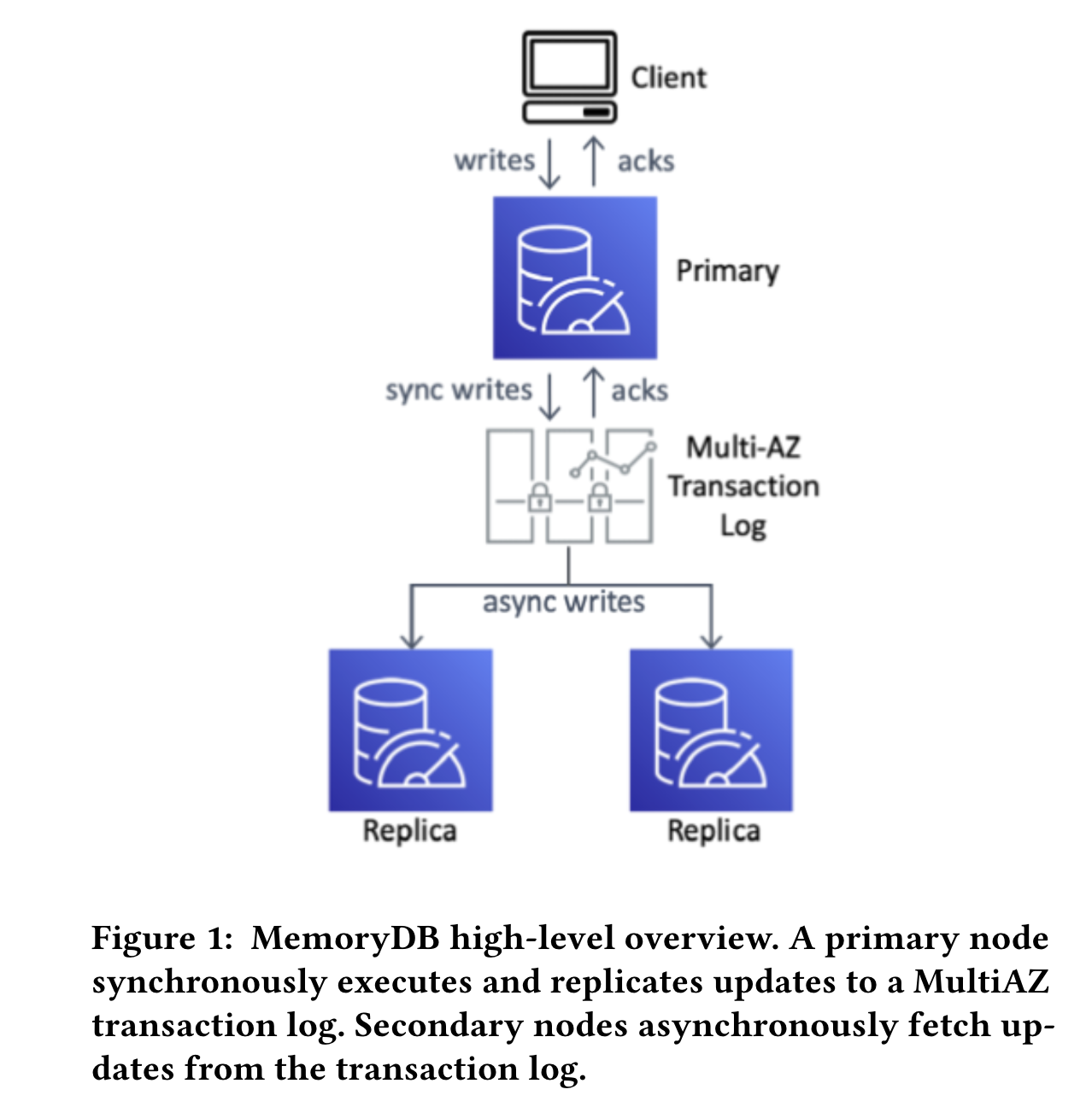
Forget trade-offs, Imagine a “database” that delivers in-memory speed with the 11 9’s durability. It was a joy to read the paper “Amazon MemoryDB: A Fast and Durable Memory-First Cloud Database”. This paper triggered me to share what I admire about its innovative approach. It fundamentally challenges the notion that speed and durability are opposing forces in database design. MemoryDB breaks the mold by decoupling the storage engine (Redis) from the durability layer (transaction log). Technically, the concept of separating storage and durability isn’t entirely new. Most systems do partial de-coupling (shipping transaction logs off boxes). However, complete decoupling, focus on in-memory performance, and the level of consistency it offers makes it unique. Redis does not offer a replication solution that can tolerate the loss of nodes without data loss, or can offer scalable strongly-consistent read Paper highlights that while Redis boasts impressive microsecond latencies and the ability...